| Overview |
The large volume of raw data, grouped into "runs", requires significant computing time to analyze -- either sequentially on a single CPU or in parallel on multiple machines. The Jlab batch farm is a large collection of (essentially) identically configured computers, permitting parallel execution. The batch farm also has ready access to the tape silo, where the raw data files are stored.
By neccessity, use of the batch farm is not interactive. Therefore, provisions need to be made to allow the analysis to progress unattended between "submission" of the batch request and its completion. The standard batch system mechanism accomplishes this via a command file that specifies the input and output options as well as the actual command to execute. Since this command file needs to be customized for every run to be analyzed, a large number of analysis jobs quickly makes this a tedious task. Additional preparations and requirements complicate this further and any serious effort will need to utilize some automation tools.
So far, these tools have usually been custom created and they have generally not been very user-friendly. BATCHMAN was created to handle all the details of the batch analysis yet be user-friendly and reasonably robust, isolating the user from the batch farm, the tape silo and their command interfaces.
| Batch Analysis at Jlab |
Analyzing on the batch farm is characterized by two steps: getting the data files and submitting the analysis job. These tasks are characterized by their main commands, jcache and jsub which are extensively documented on the Jlab Scientific Computing User Documentation web page.
| Gen01 Specific Considerations |
Unfortunately, this puts us at odds with another consideration: the batch computers do have access to the tape system's cache disks and to the CUE work disks, so we could have the batch jobs work in these directories. This, however, would mean that every bit if data input and output occurs across the network. While this is generally acceptable and certainly commonplace for interactive jobs, it does represent a significant inefficiency and increases the potential for system problems affecting the analysis.
It is much more efficient to simply copy all the requisite files to the batch computer's local harddrive and have it process all data I/O locally. The results are then copied to the work disk for final storage when the analysis completes. This also reduces the time during which the analysis is succeptible to network problems.
Implementing this approach consistently, then, requires that we copy our runtime setup and the raw data files to the local disk before starting the replay. However, each of our raw data file segments is as large as 2GB so only runs that do not have more than 2 segments (discounting runtime setup and output) fit into the 4GB disk space allocated for each job by the computing center. While this does cover at least 1/2 of our runs, it leaves a large amount of data non-analyzable.
We could easily solve this problem by using a mixed approach, copying only the runtime setup to the batch computer's disk and accessing the raw data remotely. This, however, is precisely the inefficiency we try to avoid -- we're not the only ones using the batch farm and we do want our jobs to run as quickly as possible.
Instead, we have implemented a different approach: Prior to starting the analysis, we copy only the first file segment of the raw data to the local disk. Then, while the analysis is proceeding, a background task running on this same batch computer, in parallel with our analysis, keeps an eye on the analysis progress. While one segment is being analyzed, the next one is copied to the local disk by the background task. It also deletes those segments whose analysis is done, freeing up that disk space.
This method does exceed the (apparently) administrative limit on the disk space available to each job, but only intermittently and only by the space used by bthe runtime setup and the output files, which is significantly less than that taken up by the raw data files.
The background task monitors the stats files to determine which segment is currently being analyzed. If this recently changed, it will delete the previous data file segment (i-1), the analysis of which apparently has completed, and then starts copying the next one (i+1) to the local disk -- the segment currently being analyzed (i) is already present, since it has been copied in previously.
| Gen01 Batch Replay Setup |
The batch replay setup, as expected by the BatchMan scripts, is illustrated in this diagram:
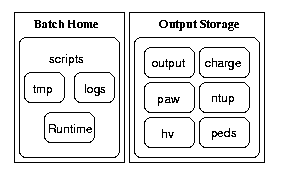
The two main groups, "Batch Home" and "Output Storage", are actually the same directory; they are shown seperately only due to their logical function. Thus, the proper Gen01 batch replay setup will:
- be contained in a dedicate directory somewhere on the Jlab work disks, presumably in a location specific to the respective user
- consist of the directories Runtime, logs, tmp, hv, ntup, peds, output, charge and paw
- and the scripts batchman, batch_deamon.tcl, batch_job and monitor_segments.
- have a complete and dedicated runtime setup (Linux!!) in the Runtime directory.
The system then works as follows:
The user controls the system's action via the Graphical User
Interface script batchman.
The actual task of determining which files are needed,
initiating the staging requests and submitting the jobs to
the batch farm are handled by the (background) script
batch_deamon.tcl.
Once a job starts running on the batch farm, the script
that gets executed there is
batch_job which in turn
invokes monitor_segments
to run in the background locally, to handle the copying of
the raw data file segments. It then starts the replay engine
and, after the analysis concludes, copies the results back
to the user's work disk directories.
| The BatchMan GUI |

BatchMan GUI click on image for full size view
The GUI displays each job on one line, 10 lines per screen; the buttons at the lower left and right serve to page forward and backwards, one page at a time, five at once, or all the way to the beginning or end of the list. For each run, the run number is displayed (far left) and the raw data file file segment count. The latter is actually a button which invokes a window listing the files explicitly. The far right displays the time that has elapsed since the current state has been entered. It only gets updated when the batch_deamon.tcl script iterates.
The remaining fields' content changes depending on the specific job status. This could be a button detailing the files that have been stage so far, or a field containing the batch system's job sequence ID. Other options include the time at which a job entered the current state, and if it completed also its finish time, and the state the job was in when it was aborted. If a job terminates abnormally, most likely some error indicator can be found here as well.
The status file contains the exact same information as is displayed by the batchman GUI. Via this file, it communicates with the workhorse script batch_deamon.tcl. They both read from and write to the same status file, updating the individual job's state as they progress. The user can change a job's state to an action request (e.g. new or kill) using the GUI. The workhorse script continually runs in the background and updates the job's status as it acts upon it.
A sample BatchMan status file corresponding to the above example of the GUI is shown here; it is in HTML format to make it more easily readable (using a web browser). This also allows remote monitoring if the file is suitably located. Upon comparison between the two, you might note the additionally listed job marked "Unknown!" It was found to be running on the batch farm under the current user ID but is not currently accounted for in the status file. The user has the option of merging this job into the task list for tracking ease.
Important! Be careful when exiting the BatchMan GUI: make sure to use the Exit button, not the X-Windows manager's "close window" icon! Otherwise, the lock will not be released (see below) and your jobs will cease to progress! The resulting exit dialog will confirm that you want to make the changes you have requested permanent. If you indicate No they will not be entered into the status file and will not be acted upon. You also get the option of not exiting after all.
| The Batch DEAMON |
batch_deamon.tcl first attempts to claim the lock file (see below) and, once it succeeds, it reads the status file. If so indicated by the corresponding flag (see Parameters), a call to jtstat is issue and a list of active and pending staging requests is obtained. Then it issues a jobstat command to query the status of the batch queue. This is checked against the status file and the various jobs' state is updated as needed. If possible, the completion of the previous state is verified prior to moving on, or an error state is assigned if the check is unsuccessful.
Abort commands (kill and restart) are executed first. Next, the list of files for which staging request have been issue is checked and the already present files are noted. If the staging system was queried, as per parameter setting, any files that are neither already present nor still in the staging task list are considered AWOL. If their staging request is older than a few minutes (to cover any latency in the task handling system), the run is terminated with an error status. If, however, all the files of a given run are present, the run is submitted for analysis on the batch farm. For newly added runs, the list of files is obtained from the tape staging system and the files are requested. Then, if indicated by the corresponding parameter setting, any unsuccessfully terminated runs are resubmitted. Finally, the status file is updated and the lock released. batch_deamon.tcl then sleeps for a certain time (see parameters) and afterwards another iteration is started.
Since all scripts that access the status file make use of the lock file, it is possible to have any number of deamons running under the same user ID and from inside the same directory (BatchMan systems running from different directories are independent by design, though they may require the user to start a batch_deamon.tcl manually). It is even possible to run them on different computers, as long as they have access to all the needed disks and can interface with the MSS tape system and the batch farm. One should probably increase the sleep time in that case, though (see parameters).
In addition to the background deamon mode, started with the command
batch_deamon.tcl &two other modes are available, primarily for debugging purposes:
In oneshot mode the script goes through only one iteration and then terminates. In this mode, it generates status messages on the terminal as it progresses. This can also be used to force an update, for example after a session with the batchman GUI. The command is simply
batch_deamon.tcl oneshotor, avoiding the extra screen output,
batch_deamon.tcl quietone
Useful mostly in the case of intermittent problems, the verbose mode generates the same messages as the oneshot mode but it does not exit after one iteration. Instead, it continues based on the same rules as the background deamon would. This requires that the command window (xterm?) in which the command was issued stay open. In exchange, a log of the progress is printed to the screen:
batch_deamon.tcl verboseor
batch_deamon.tcl interactive
| BatchMan Parameter |
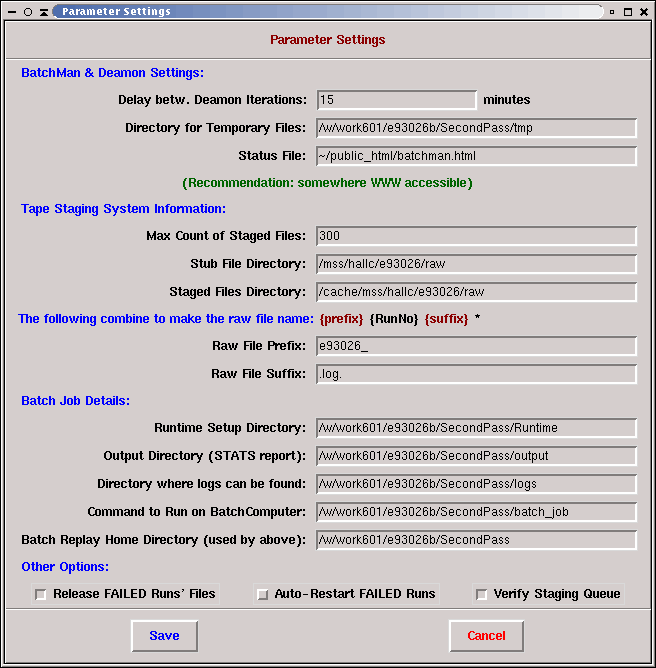
BatchMan Parameter Dialog click on image for full size view
Here is a description of the parameters and their default values ({thisdir} refers to the directory in which your batch replay is located):
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
For completeness only: The defaults used by batch_deamon.tcl in the absence of an entry in the parameter file (or the absence of a parameter file) is NOT the same as the GUI dialog's default. The latter are recommended values which have high expectation of giving satisfactory results, while the former are designed to allow operation in even unusual situations. Don't push the issue, though, a missing or incomplete parameter file is bound to cause problems!
| The LOCKfile |
The current status of all your jobs is stored in a file. This status file is used by BATCHMAN and by the automatic background process to communicate.If you feel that no other process ought to be claiming this lock right now, get the PID from the lock file and check if such a process exists. If so, you should give it a few more minutes and then, after first checking if the lock is still taken and by this same process, you could kill the process before deleting the lockfile.Right now, it appears that the background process is updating your status file. To ensure that you do not overwrite these updates, you are given only read access to the status file until the automatic process is done. Usually, this only takes a few moments -- another check will be done every ??? seconds.
However, it is possible that the "lock file" is actually a remnant from an aborted or crashed old process. You can exit BATCHMAN and check the contents of the lock file for the PID of the process that created it. If that process is no longer running, you can delete the lock file and restart BATCHMAN. Your lock file is ???.
Keep in mind, though, that a process running on another CPU might also access this same lockfile and then it will not show up in this CPU's tasklist. This will of course only be an issue if you ran batchman (or batch_deamon) on this other CPU and in this same directory. Also you should check the modification date of the lockfile: if your sleep time is too short, you will have a hard time catching batch_deamon asleep and the lockfile will seem to be permanent. Simply run BatchMan, even if it can't get the lock, and click on "Params" to open the parameter window to change the sleep time.
The best way to avoid problems with the lockfile is to make sure you exit the BatchMan GUI properly -- via the "Exit" dialog. Taking the shortcut of closing the window via the Xwindows window manager (the corners of the window frame) id certain to cause these problems. (Note: if you know how to force a tcl script running under wish to use *my* exit command, please let me know so I can bypass this problem.)
| BatchMan Job Progression |
The following chart hopes to illustrated the different states known to BatchMan and how a transition from one to another is initiated, be it by user interaction or due to job progression.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||