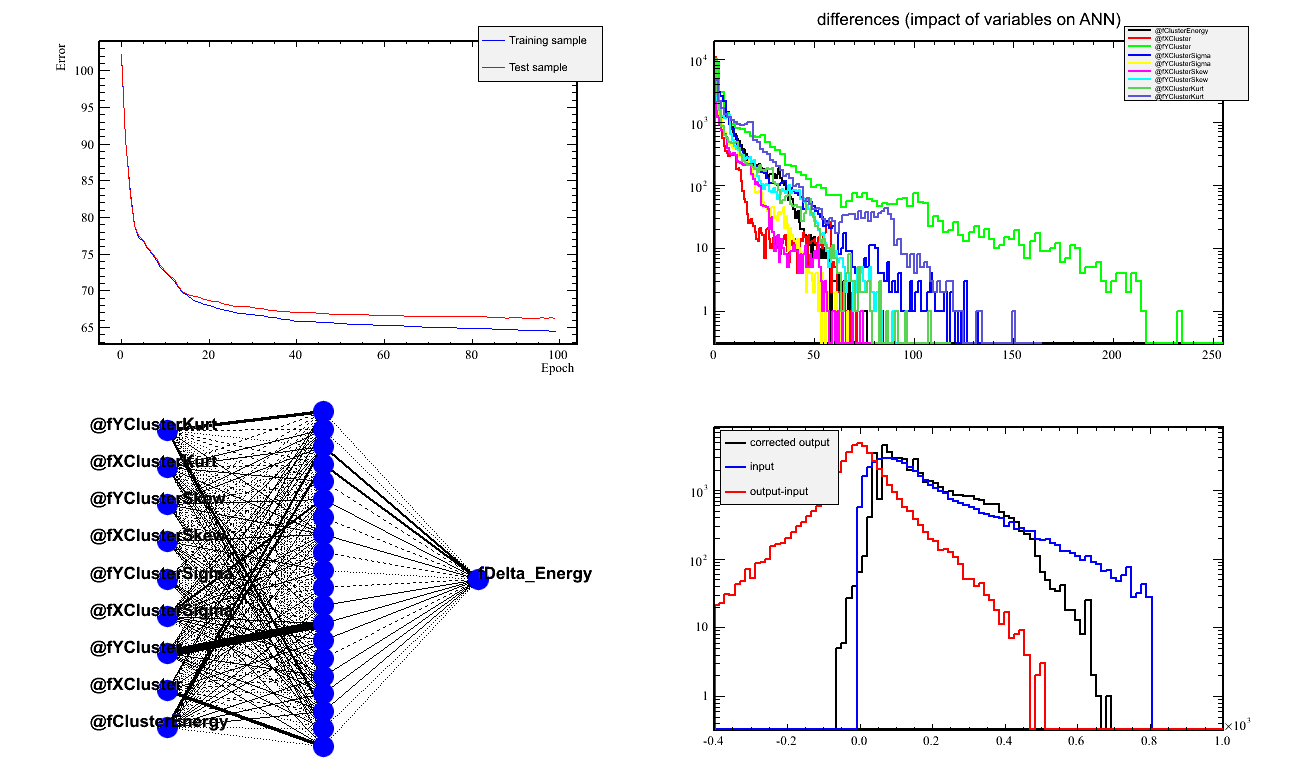
Network training
- 25 hidden - 100 iterations
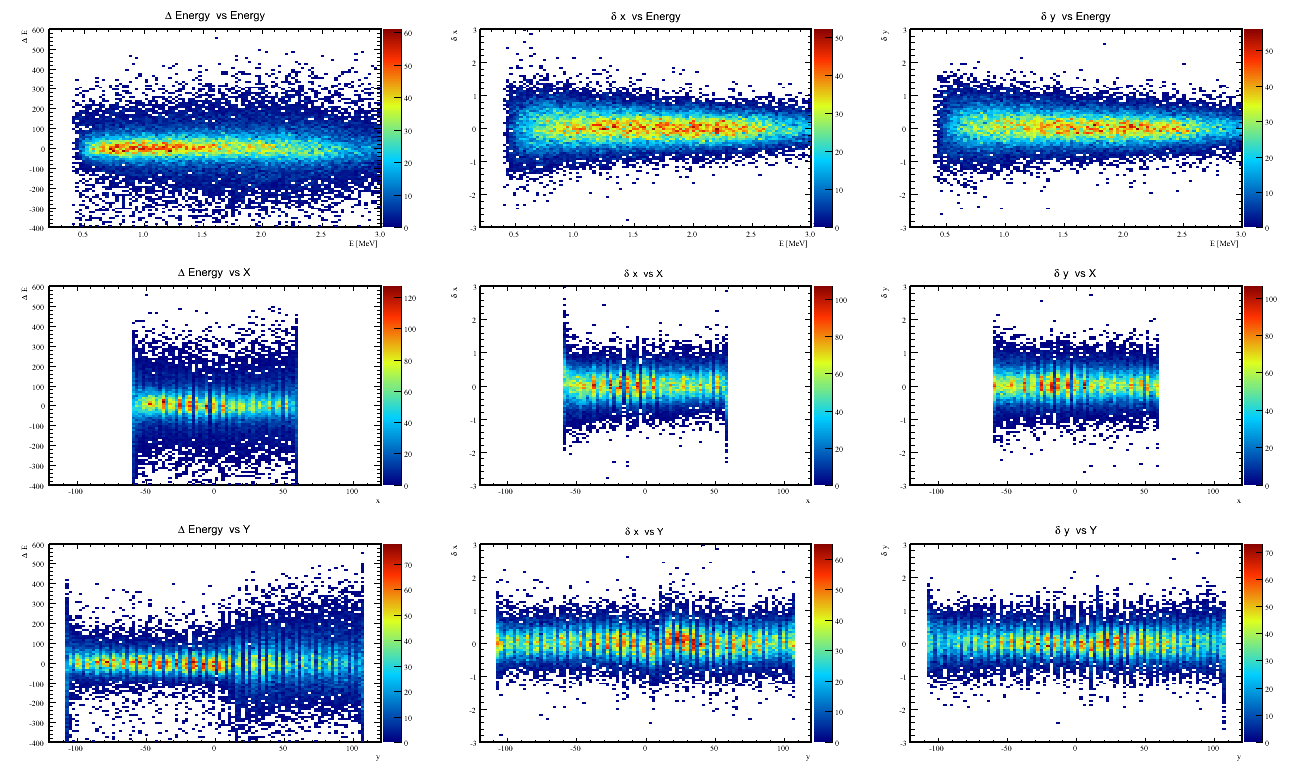
Observations
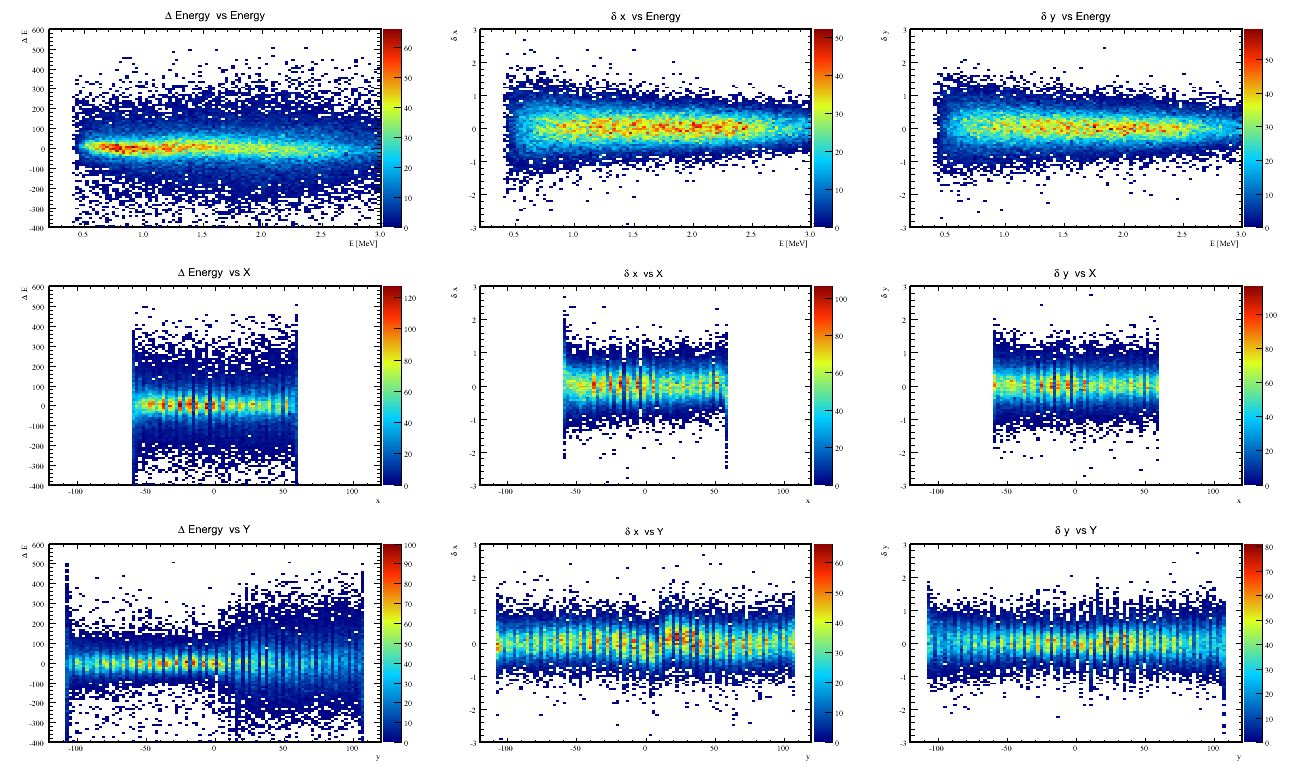
- There seems to be a discontinuity in the treatment of delta_x in going from protvino to RCS. See central bottom plot
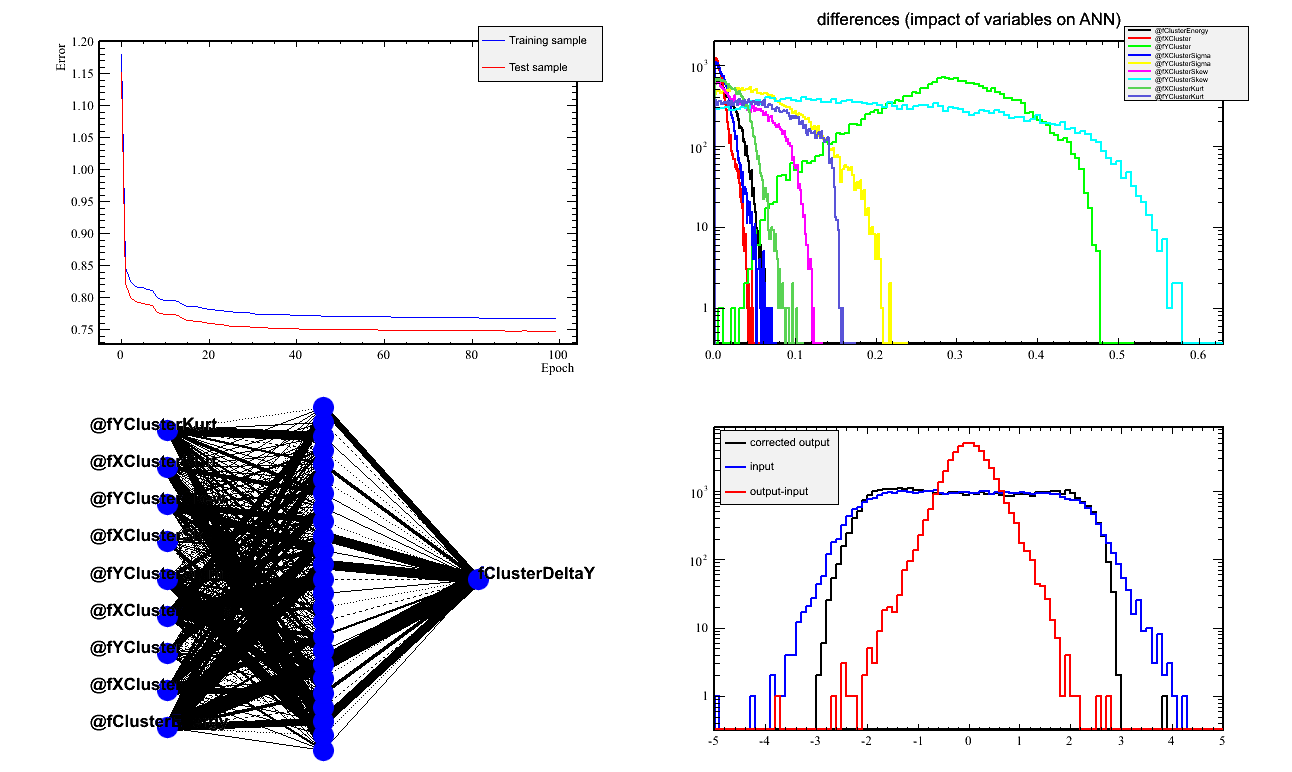
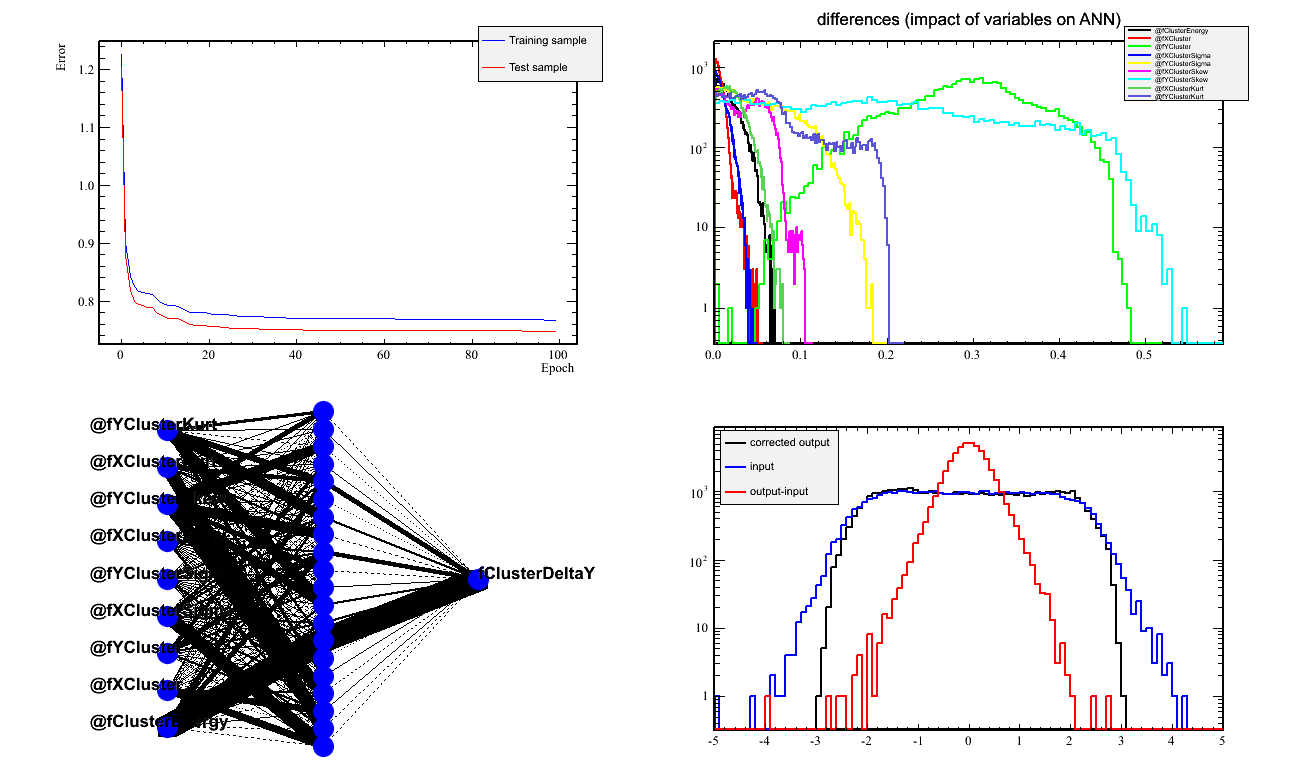
- The Y network works nicely. Looking at the impact of variables,
the most sensitivity is on the "Y" inputs, ie, cluster y, y-sigma, y-skewness, and y-kurtosis.
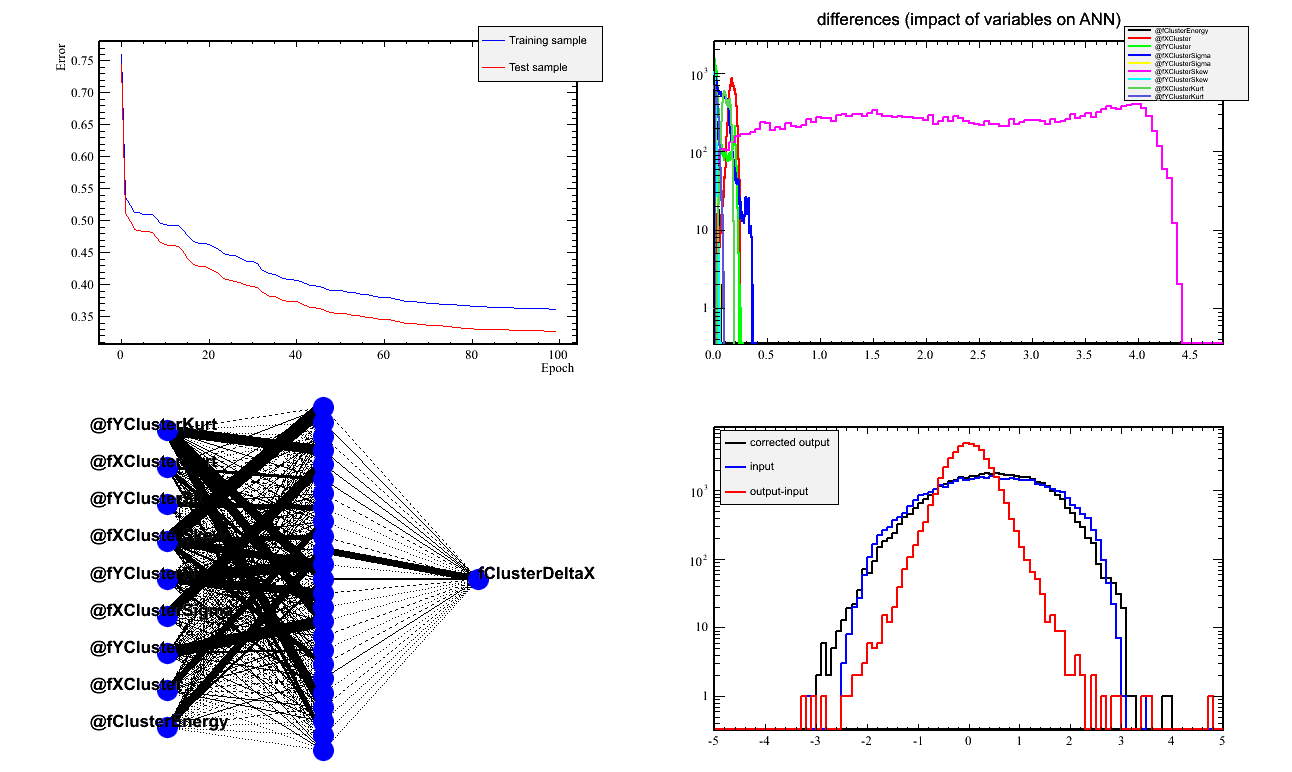
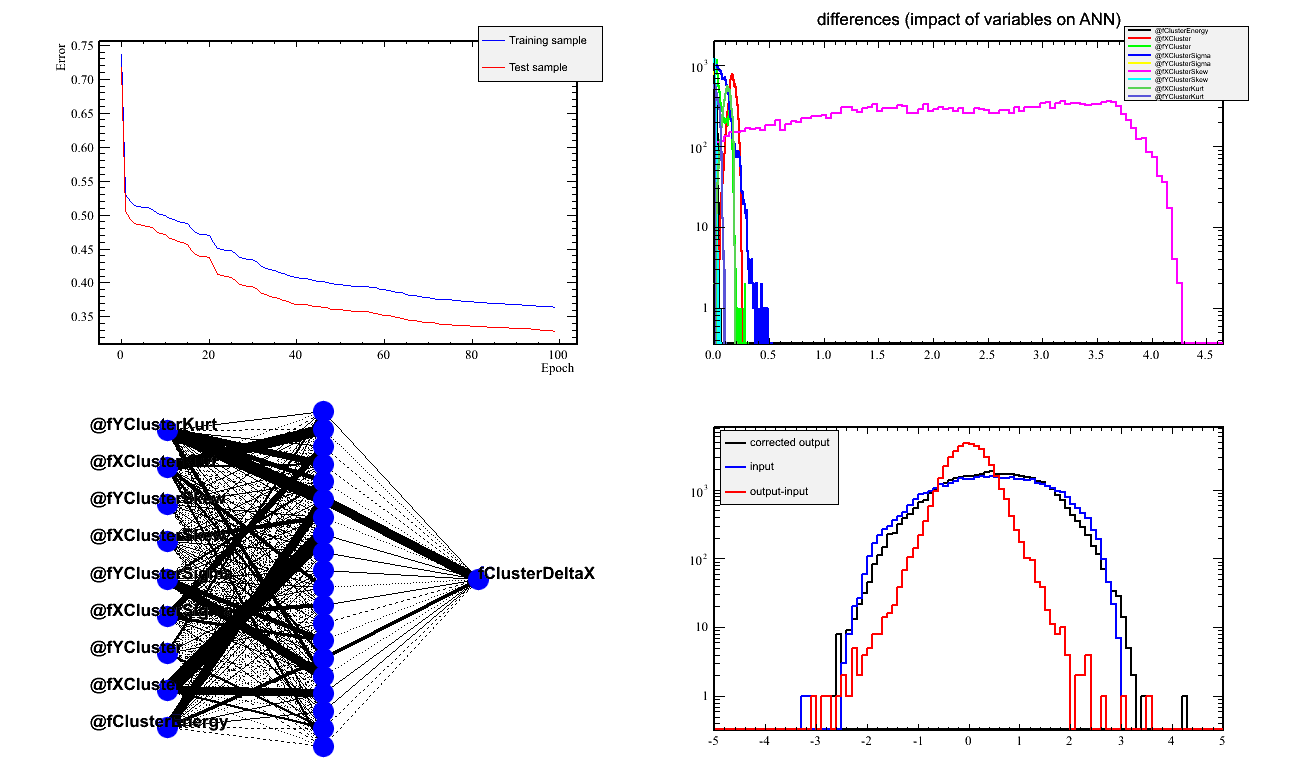
- The X network looks good, but has a strong dependence on the cluster's X-skewness.
this could be coming from the protvino-rcs border.
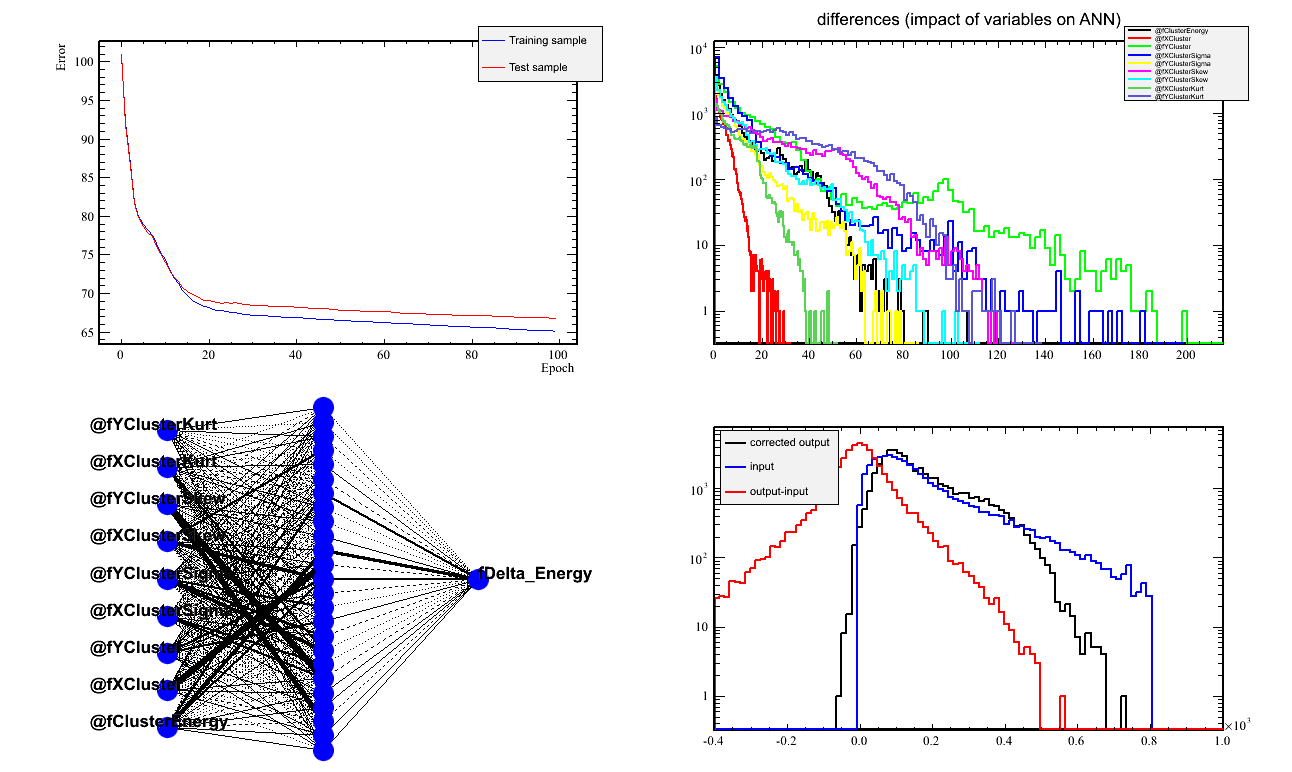
- The Energy network does not look that great. Likely due to non-inclusion of the raster, and hence the extra B.dl that occurs in the target volume depending on the rastered position. I will add the raster info to see if I can get improvement.
- 20 hidden - 100 iterations
The results are very similar to 25.
- 30 hidden - 200 iterations
Now I am using the class ANNDisEvent6, which has the raster x and y positions as input neurons.
- 20 hidden - 20 iterations
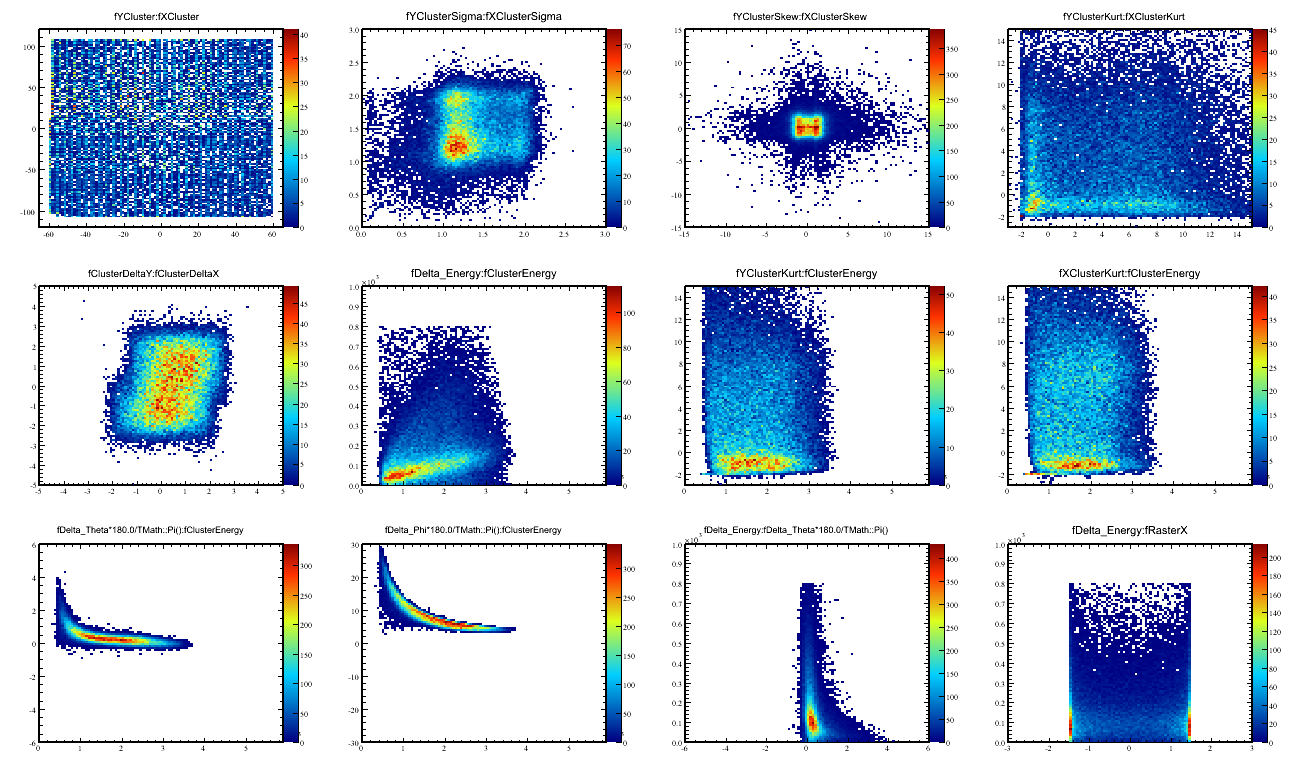
Looking at the input plots, the bottom right most shows delta_E vs the raster-x. There seems to be a strong dependence as anticipated.
- 40 hidden - 400 iterations
- 2 Layers 20:5 hidden - 500 iterations
Add a cut while creating the NN training data set. For the BigCal plane, the energy at the bigcal plane has to be with 30 MeV of the thrown particle. This avoids too much energy loss etc...
Todo
- Currently the "thrown" particle's vertex is used for the raster position. Ideally the
HallCBeamEvent should be properly set.
- Make sure that the raster simulation matches the reconstructed. Right now there is no fast raster simulated.
- Also, there is no addition randomness added.
- Calibrations with new position
- New packing fractions
- Cherenkov ADC cut
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}