Gen01 syncfilter preprocessor
Executive Summary
During Gen01, the DAQ was working independently from the scalers.
Since there was no provision for any direct correlation, we cannot
simply match the results from the replay with the scaler values.
Further, the beam current monitors had a minimum reading well
above 0, so even without beam the scalers were accumulating charge.
But even the DAQ itself had some issues that the replay engine is
ill equipped to handle: if any part of the DAQ system crashed during
a run, the raw data stream will be lacking an end-of-run marker,
which causes the replay engine to crash, without outputting
the analysis results. And there is a potential synchronization
problem between the different FastBus crates.
These are the primary reasons why we need syncfilter -- it
takes care of all of them. All you have to do is pipe the
data to be analyzed by the replay engine through syncfilter.
Pipes are frequently used in the UNIX world; they are
simply a chain of commands that the data "flow" trough.
Our replay engine is able to use this same approach, including
the identical syntax. If we want to have the data modified by
syncfilter before the replay engine gets a hold of them, all
we need to do is modify the source file specification (most
likely, this is in REPLAY.PARM). Instead of
g_data_source_filename = 'e93026_%d.log'
we simply use "|syncfilter" -- note the vertical bar --
to indicate that we want the
data to be "piped" through syncfilter first:
g_data_source_filename = '|syncfilter e93026_%d.log'
syncfilter passes the prep'd data on to the replay engine and it also
generates two output files. First, because now syncfilter is
responsible for reading the raw data files and therefore has to handle
the switching from one file segment to the next, is a short status
file, comparable to the file statsrunno.txt,
which indicates the number of the raw data file segment currently
being processed.
This file is called syncfilter.stat
Further, a log file called syncfilter.log is created.
This file contains occasional progress indicators, indicators of (fixed)
problems and a summary output. This summary is also an
important aspect of syncfilter: it contains the proper scaler counts
to use for the analyzed data. These are total charge by helicity state
and the corresponding time, allowing for proper event rate calculation
and current determination. A sample log file summary is explained
here.
|
The replay engine commonly used to analyze Jlab's Hall C experiments has
no event memory. This means that each event is processed as if it was the
only event in the entire run. Only histograms and scalers accumulate
information from event to event but without any correlation.
This means that the data stream can only be processed sequentially; no
out-of-order information can be used in the analysis process.
The data stream, however, includes numerous special events which
contain information about the chunk of data that was just processed --
too late to change the analysis parameter for those events.
To rectify this limitation, a pre-processor was created. The raw
data are passed through this filter and flags are inserted to indicate
the validity of the subsequent data.
Historically, the filter was used to detect synchronization problems between
the different FastBus branches (see below), thus the name syncfilter.
Since Gen01, this functionality has been significantly extended.
All functions reduce to this, though: syncfilter inserts fake events
into the raw data stream which indicate the conditions during which the
subsequent data were acquired; this information is otherwise available only
AFTER these data.
Since this is a filter, the data enter and exit as streams thus allowing
redirection. This enables us to use syncfilter in a practically transparent
fashion in the analysis engine's raw data file source specification.
The following detailed discussion of syncfilter necessarily involves
particulars of the experimental setup, especially DAQ related issues,
and also some software items. To avoid confusion, I will briefly
describe the relevant items here.
The electronic signals from the various detectors and other apparatus in the experiment
enters the data stream recorded on tapes via two alternate avenues: the FastBus DAQ
electronics and the scalers. A few other systems also exist, but their handling
parallels one of these paths.
Prompted by a trigger, the FastBus path processes distinct events,
each of which is completely independent of the others. The event
data are read from the electronics by the DAQ system CODA and written to file as
they occur.
The scaler system works differently. By intent, scalers continually respond to the
signals fed into them and keep count. Once in a while, they are read out (also by CODA) and,
possibly, reset.
For Gen01, there were actually three different sets of
scalers, distinct in the frequency with which they were read out. The traditional
set, usually referred to as the asynchronous scalers, are read by CODA
approximately every 2 seconds and their current value is then recorded into the
data stream. This occurs together with the sync event
which re-establishes synchronization between the different parts of the DAQ.
We will refer to this two second period as a sync interval.
The helicity scalers, on the other hand, are read at the end of every
helicity interval, the period during which the beam helicity is fixed,
~1/30 seconds. At the boundary between these "helicity buckets" the beam's
helicity may change. Again, CODA inserts their values into the data file
as a helicity event. It is important to realize
that the two periodic
events (scaler event and helicity event) do not have a fixed phase
relationship, i.e. they occur completely independent of each other.
The third type of scalers used in Gen01 is the event scaler. These are
actually a hybrid of a scaler event and a DAQ event: they occur at the same time
as a triggered DAQ event and are inserted into the data together with the DAQ
event.
The data-handling software CODA does a good amount of error checking as it
processes the different events' data. At times, if trouble is detected, an
error event is inserted into the data stream which is coded to indicate
the specific error condition encountered. Some of these errors are found before
the data are processed (many preclude the processing in the first place) and
then the error event will be recorded in place of the data. Other cases, however,
can only be detected once the data are processed and then the error code follows
the data it relates to.
The raw data are recorded to a computer file which is eventually stored on tape.
These data are later analyzed using a program called the replay engine
(sometimes just replay). Since much of the analysis of experiments that
run in Jlab's Hall C is similar, the standard code package CSOFT was
developed. It provides a standard analysis engine, including the many utility
routines that interface with the raw data file and decipher any hardware-specific
data formats.
|
What syncfilter Corrects (or flags)
|
There are few data-related problems that can be repaired but many can
be bypassed, if only by discarding some amount of the data. The
actual data analysis is not what syncfilter is meant to do, instead
it is intended to provide a way around some of the shortcomings of a
real-world DAQ system. It therefore will not alter the recorded data
but instead it adds additional information which is then used to make
appropriate decisions in the replay engine. Some independent accounting
of certain quantities does however take place. The following describes
the various conditions syncfilter is designed to recognize and relay
to the analysis engine in a fashion that allows the engine to deal with
the issue in a timely manner.
fastbus crates out-of-sync
The DAQ uses several FastBus crates to process the data, each operating
fairly autonomously. The respective data need to be matched up, however,
so the crates have an internal counter which tracks the events.
Approximately every 2 seconds the DAQ generates a synchronization event
during which these counters get matched up. This event occurs together with
a scaler event during which the asynchronous
scalers are read out (and their data inserted into the data stream).
If at that time it is found that the event ID numbers do not match, an error
event is inserted into the data stream to flag this condition. Essentially,
this means that the last 2 seconds worth of data need to be discarded since
we do not know at which point the error occurred. We do know that the error
occurred in this latest sync interval so only those data are affected.
Note that the flag necessarily follows the data.
scaler sync problem
Similar to the FastBus sync error, this is a synchronization problem in
the scalers. Same effect as the FastBus sync, except that the only data
affected are the scaler data. But we need those, so out go the correlated
data, too. Again, this follows the data in question.
latch sync problem
Another sychronization error. This one is with the latch -- I don't know
how many latches there are. Actually, all I know is that this is where we
get the beam helicity from -- kindda vital, so the data hit the bucket
(trash, not helicity!). And again, this follows the data in question.
missing end-of-run marker -- run ended abnormally
This one is different -- the data are ok. But our analysis engine doesn't
like it and has the tendency not to properly close its files, which PAW
in turn doesn't like -- especially for Ntuple files. Also, we like to
have a scaler read with our data and the final one is missing.
So we put a flag after the last asynchronous scaler read to mark the
(improper) end of the raw data file. This makes engine is happy, too.
low beam current
This one is the reason why I started looking at this at all (well, wanted
to -- a need existed anyway). Our beam current measuring devices (Beam
Current Monitors) tell us not only the instantaneous beam current but
also allow us to track the accumulated charge, even separately for each
beam helicity.
Unfortunately (there's that word again), they don't drop to zero when
there is no beam. Actually, they act up way before then in that they
become non-linear. So without beam they indicate some beam and at very
low current they indicate slightly higher charge flow. Not good if you
are integrating the readings over time. Since we cannot actually correct
the readings (scalers only keep the sums, not the details) we have to
selectively discard scaler reads that indicate that the average current
was too low to be reasonable.
The actual determination of the beam current is based on the accumulated
charge as indicated by a scaler. Since the current is continually measured
and the scaler integrates these values into an amount of charge over a
certain time interval, we need to properly define the start and the end of
the interval. We also want the interval to be as short as possible to
limit the impact of any problems. The scalers which satisfy these
requirements best are the helicity scalers: the asynchronous scalers have a much
longer time base, and the event scalers lack a well-defined time interval;
the random nature of the occurrence of an event precludes us from using another
(prior) physics event as a reference.
This means that for each helicity interval we extract from the corresponding
helicity scaler a value for the charge accumulated in the interval
and a measure of the elapsed time period. Properly normalized, the ratio provides
the mean current for that ~1/30 second interval. Using the time recorded by
the scaler instead of the expected time interval allows us to eliminate any
inconsistencies or fluctuations but has a further advantage:
computer dead time
One set of the helicity scalers accumulates signals that are gated with a
flag indicating the DAQ's readiness. If the DAQ is busy processing the
previous event or otherwise occupied, physical events that might be observed
by the electronics will nonetheless not be seen by the DAQ. By considering
only the charge and the time when the DAQ is able to process events, we
establish a direct correlation between the physical events and the beam
charge.
Otherwise, this inconsistency (the scalers' dead time, if any,
is different) would require a separate correction -- one which is not easy
to define without any direct correlation.
Note that this does not address any rate dependence in the response of the
electronics (also called electronics dead time). The boundary between these
is not easily explained but in practice quite well defined.
After the input and output streams have been opened, using the standard
CSOFT routines, the main processing loop is entered (see figure).
Here, the individual events are read from the input stream and, after
some basic information is extracted, the event is added to the main data
buffer. Later, this buffer is dumped to the data output stream.
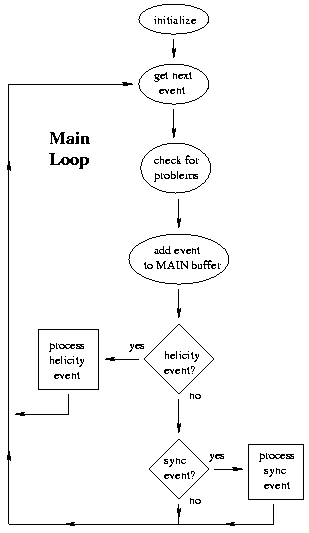
The buffer is meant to contain all events of a single sync interval.
While the data are in the buffer, we can still change the order of the
information that is output:
if the input stream ends before an end-of-run event is found, we can
output a fake end-of-run event before we output the last bit of data.
Similarly, if at any time during this interval there is a synchronization
error, we can output the corresponding flag before we output the data,
thereby enabling engine to skip the questionable events.
We have, however, an independent, smaller grouping of events into the
helicity buckets. The respective boundaries of the two groupings can
occur at any point relative to each other and the relation can vary
over the course of the run. This means that we have to hang on to the
buffer until the helicity bucket, in which we were in when the sync event
occurred, has ended.
In the meantime, we need to keep buffering the new
events being read. We also need to hang on to the first part of the
helicity bucket that is at the very end of the previous sync interval, as is
illustrated in the following, and thus are stuck keeping the entire prior
sync interval's data around. The reason is this: if we find that we have
a sync error somewhere in the current sync interval,
then we need to discard the entire interval's data.
However, we
have to deal with the data in increments of helicity buckets, so we
need to discard the current sync buffer and the balance of any
partial helicity buckets. This is the beginning of the first bucket,
located at the end of the previous sync interval, and the last bucket,
at the beginning of the next sync interval.
We therefore need to keep the data from the previous sync interval
available until the current interval has ended (a sync error might not
show up until the end). Since the other end corresponds to data not yet
read in, we just need to remember to flag them in the next sync interval.
We therefore have two buffers, the one currently being
filled (MAIN) and the previous one (OLD). When a sync event occurs, we dump the
contents of the second, old buffer to the output, thereby emptying it.
The data from the main buffer are then moved to the (now empty) old
buffer, freeing the main buffer for more data (since all
this is coded
in C, we don't actually move the data but exchange the buffers identifiers,
which is faster and safer and the "C" thing to do -- the effect is the same).
If the buffer being dumped has a sync error, a corresponding flag event is
output first.
At the end of the input data stream, we first output the contents of
the old buffer and then the data in the main buffer, inserting sync error flags
into the output stream as needed. If the maikn buffer does not terminate with
a proper "end" event, we also insert our fake end marker before we output
the final main buffer.
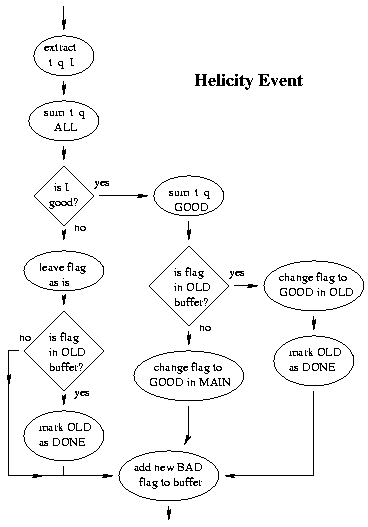 As the events are processed and added to the buffer, we keep an eye out for
helicity events. If we find one, we extract time and charge information
about the helicity bucket whose end is indicated by this helicity event.
After the helicity event is added to the buffer, we also add a flag event
to the buffer -- a fake event which is intended to contain information about
the subsequent events, which have not yet been read. Instead, we
keep track of where in the buffer the flag event is located and, when we
reach the next helicity event, we modify the contents of the flag event
to reflect the state of the beam current during this bucket.
So every helicity bucket will be bracketed by a flag event at the beginning
and the helicity event at the end. The flag event is just a precursor of the
information that the helicity event will provide -- too late to change a
linear analysis. This allows us to not
modify the experiment's data themselves and still pass information to the
replay engine about the data yet to come.
As the events are processed and added to the buffer, we keep an eye out for
helicity events. If we find one, we extract time and charge information
about the helicity bucket whose end is indicated by this helicity event.
After the helicity event is added to the buffer, we also add a flag event
to the buffer -- a fake event which is intended to contain information about
the subsequent events, which have not yet been read. Instead, we
keep track of where in the buffer the flag event is located and, when we
reach the next helicity event, we modify the contents of the flag event
to reflect the state of the beam current during this bucket.
So every helicity bucket will be bracketed by a flag event at the beginning
and the helicity event at the end. The flag event is just a precursor of the
information that the helicity event will provide -- too late to change a
linear analysis. This allows us to not
modify the experiment's data themselves and still pass information to the
replay engine about the data yet to come.
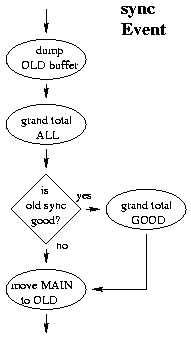
The flag also is used to warn of another, the previously discussed issue:
the last helicity bucket in this sync interval is most likely at least
partially in the next interval. If that next interval has a sync error,
this overlap bucket must be discarded as well. Therefore, the pointer
to this flag is specially saved for that purpose. The flag event has
different data words for different conditions, though the event ID is always
the same.
Each helicity event contains the data
from the respective helicity scalers, once as total accumulated value and
also the most recently read data. Since it occasionally occurs that the
DAQ cannot read the helicity event as it occurs, successive events may be
summed together into one. In that case, the last read is not useful as
it does not reflect the summed helicity events. The previous value of the
accumulated scaler is therefore remembered by syncfilter and at the next
helicity event the difference between the new and the old accumulated value is used as
the latest data.
Since syncfilter has to decode the beam current anyway, and therefore the
incremental charge accumulation and the elapsed time, it also keeps track
of the totals of these quantities. This is especially useful as the
engine's processing of this information is not centralized and thus not
quite as definite as syncfilter's.
After the charge and the time information has been decoded and properly
normalized, we take the ratio as the average current and, depending on the
resulting value, consider this last helicity bucket (or the sum over
several) to have good or bad current. If the current is good, we add
the time and charge to the good subtotals; they are added to the overall
subtotals in either case. At this time, syncfilter also updates the flag
inserted into the buffer after the previous helicity event, thus indicating
the state of the current for the helicity that just concluded.
When the buffer is swapped due to a scaler event, we also take the subtotals
of time and charge of the helicity buckets and add them to the run's grand
total sums.
The "all" value is just the sum of the "all" subtotals, while the "good"
grand total only includes "good" subtotals from sync intervals without
synchronization problems. So we have one sum including everything and
one sum including only "doubly good" charge and time, all separately
for each beam helicity.
The syncfilter log is intended to be more hardware-centric than
the replay log and thus they will report problems differently.
Also, to improve readability, redundant duplicates are replaced
with blanks, if possible.
In addition to initialization issues, syncfilter is set up to handle
a few special situations automatically.
One of these is the occurrence of a sync event being bracketed by
helicity events. This necessarily results in the second of
these not having any charge accumulated and thus a bad current flag.
Since the handling of these flags in the engine was optimized for
state changes, we
simply identify these sequences and assign the last valid
state to the redundant helicity event.
syncfilter has one input stream and three output streams: data in and out,
and report/log and status. Where each stream goes is determined by two optional
command line arguments: the first one is the source of the data (input),
and the second one is the data output. Both are optional (you can't have
the second without the first -- how would it tell it's the second one?!)
and if unspecified they default to "-" which represents standard input
or output, as the case may be. You can also explicitly specify "-" so
that you can have the data source be standard input but the output is to
a file (the otherwise impossible case).
The log is either output to standard error, if the data are not output
to standard out, or to the local file syncfilter.log. The status file,
always syncfilter.stat, merely contains the
number of the input file segment currently being processed, so that our
batch system can continue working, since the engine's STATS report no longer
knows about the file segment number, as the segment switching is now taken
care of by syncfilter.
Since syncfilter is implemented as a filter, it has no concept of file names
(aside from what it passes to the CSOFT routine to open the file) and can
therefore not extract the run number therefrom. The output files will thus
always have the standard names syncfilter.log and syncfilter.stat
in the local replay directory. If they are to be preserved,
they need to be moved or, better, renamed.
There does not seem to be much point to preserving syncfilter.stat beyond
the current analysis, though.
The beam current limit is actually checked against BOTH beam current monitors
and either one indicating current above the limit is sufficient -- this is
meant to preclude problems if one BCM fails. As of this writing, the BCM1
calibration constants in the code are absent and the BCM2 constants are used.
This results in the current indicated by BCM1 being 5% too low, but this is
too small of a deviation for the current limit to be materially affected.
The principal sources of problems with syncfilter, though fairly rare, are for one
the case where we exhaust the size of the buffer before we encounter a
scaler event, and the other is a second scaler event before we had a
helicity event, thus requiring a third, non-existent buffer. If need be,
both cases can be accommodated by changes to the code, for the former by
simply enlarging the size of the buffer. However, neither ought to occur
and there is good reason to suspect more serious problems with the data if
these errors do occur.
The latter case is partially addressed by merging
the main (current) buffer onto the end of the old buffer -- provided there
is sufficient room. This should account for the case of a sporadic extra
sync event which occurs less than one helicity bucket away from the last sync
event. In that case there shouldn't be much data around; however, since we
only have one buffer to hold both sync interval's data, the entire buffer
has to be declared bad if either of the merged sync intervals' data are doubtful.
The fact that CODA will at times merge multiple helicity buckets into a
single event is also a potential issue. It might even be worth considering
to discard the data if the number of helicity buckets summed together gets
too large, as the average current becomes less meaningful. The event does
include information on the number of buckets summed and syncfilter does check
this count against the accumulated time to verify that the numbers are
consistent. This is important mostly because the buckets are summed separately
for the two helicity states but the count of summed buckets is only the total.
Also, if the more buckets get summed together, the greater the chance that a
sync event occurs in between. This would require the buffer to not be flushed,
a situation described above.
If the engine crashes, syncfilter is automatically terminated and no
summary can be output. Occasionally, for unknown reasons, engine exits
too quickly for syncfilter to finish outputting its report summary as it
is (again) terminated. Some information may then be extracted from the
replay log as special coded events contain some of the data.
This functionality could possibly be extended to obviate the syncfilter
log entirely and maybe even the syncfilter status file.